Echo360 Clients Reap Benefit of Modern Cloud Architecture
Back in 2015, Echo360 set out to build an entirely new video platform that combined a complete set of video learning tools with student engagement and instructor analytics, and we knew we needed to do this in the cloud. Given that we were already the leading vendor in lecture capture and had a large install base doing campus-wide classroom recordings, this was no small undertaking because our cloud platform needed to support all our existing client needs as well as our vision for the future of video learning.
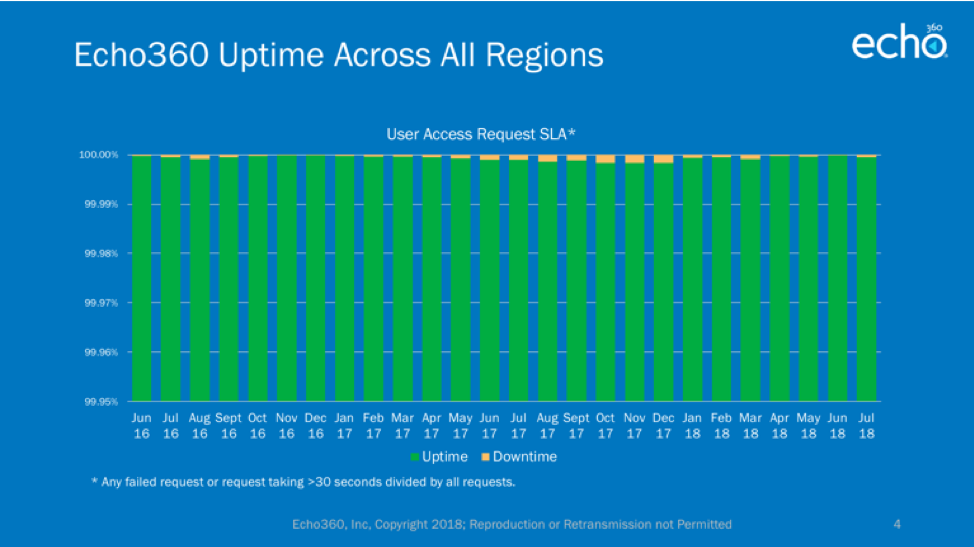
The good news is that all but a few of our existing clients have completed their move to the cloud and the benefits they are reaping are clear from our uptime statistics. The Echo360 platform is able to offer superior uptime and user experience because we didn’t simply port our existing platform into cloud hosting. In fact, we were already doing that back then. Instead, we chose to build a modern Service-Oriented-Architecture (SOA) that would meet the needs of our clients for years into the future, and this architecture is important to understanding our uptime statistics.
In the table above, we count a downtime event anytime a request takes more than 30 seconds to complete, but the reality is most “outages” in our current platform only affect one service at any given time. So, for example, an admin may experience a downtime event creating a new user, while the student video experience is completely unaffected. That’s because these users are interacting with different services on the platform. And once we detect an issue in a service, it is restarted automatically and usually returns to normal operation at that time.
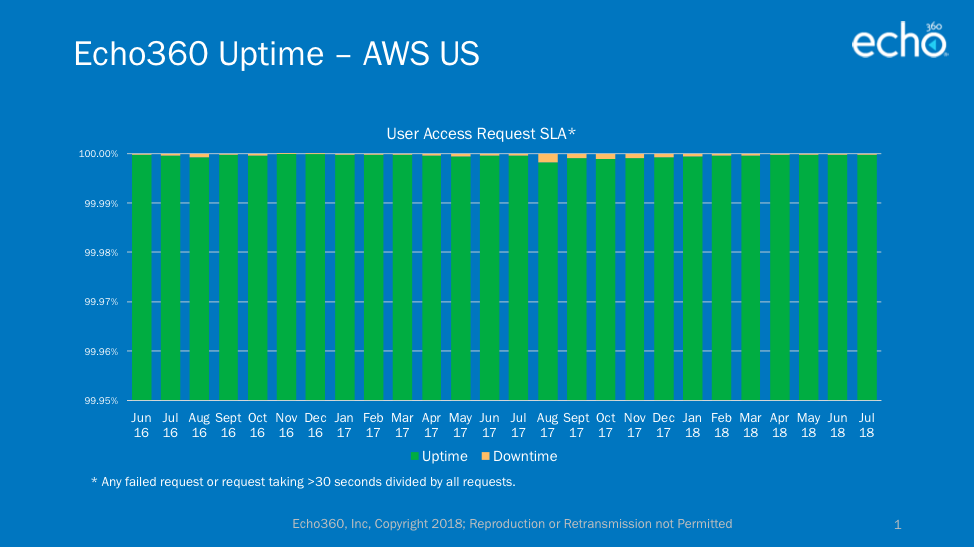
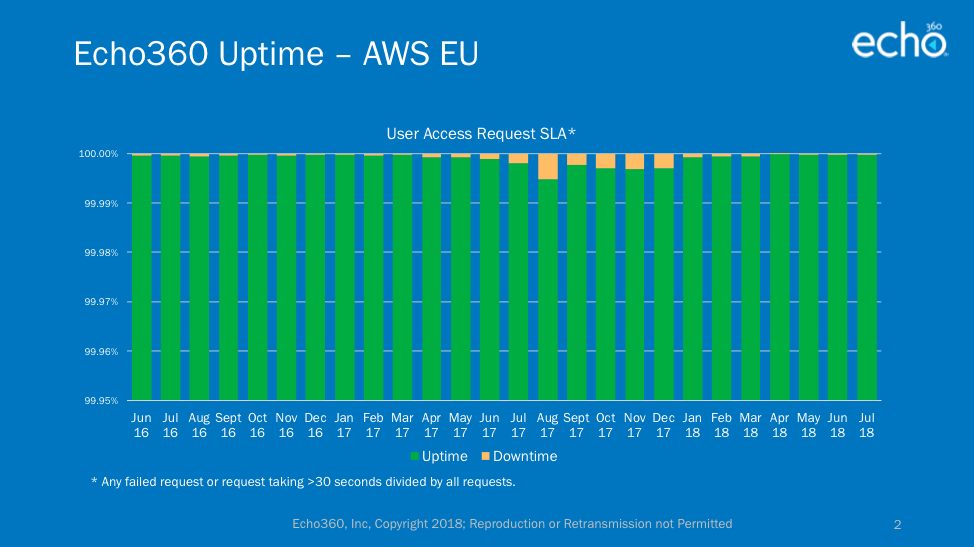
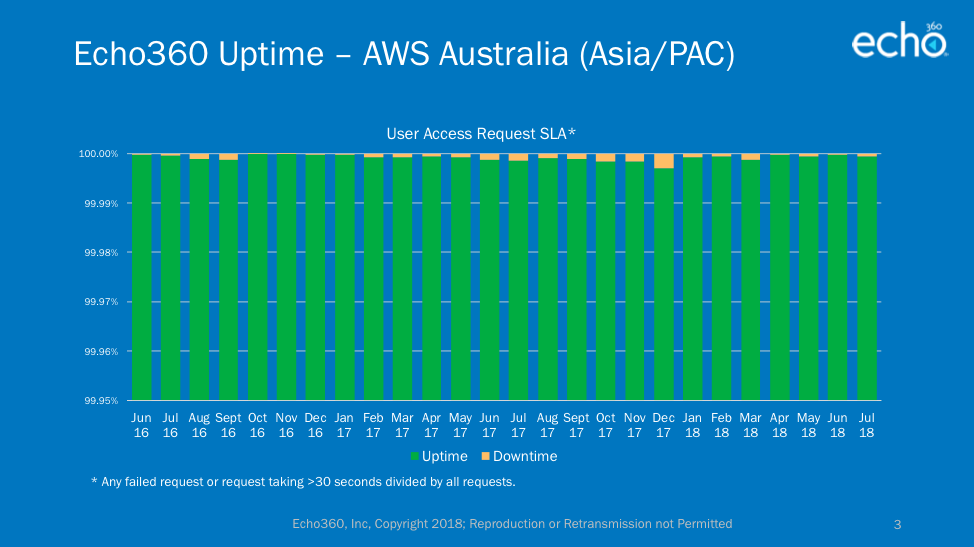
As you may know by now, we built our new platform natively on Amazon Web Services (AWS) and we currently host instances in four different AWS regions around the world. The chart in the header refers to our combined uptime across all regions and the charts at the bottom of the article are for each region, individually (note: Canada regional hosting is too new to provide data at this time). There is always the possibility that an entire AWS region goes out or is unreachable because of network problems, but these events affect all applications housed in AWS, not just Echo360.
Another thing to note is that even when an entire AWS region is unreachable, all capture endpoints, both hardware and software, continue to function at our user sites and captures are uploaded and processed as soon as the platform is reachable again.
If you are a current Echo360 user, we are confident that you are enjoying your experience with our state-of-the-art platform. And if you are considering moving to Echo360, we hope this information will help with your decision, so feel free to reach out to us if you have any questions or need to see more data to support your evaluation. You can contact us here.
Regional Uptime Charts
Learn more about Echo360.